

Updates
- 4/23/2019: there are a few issues I’ve run into in Sequelize 4. Mainly, createdAt & updatedAt are broken. I’ve also encounted issues with table name capitalization while running migrations on Mac vs Ubuntu. I do have fixes for these, so if needed, drop me a line with the email form and include “HALP SEQUELIZE PLS” in the email body. I’ll update the post as I have time.
- 3/2/2018: added a stab at many-to-many associations;
- 10/31/2017: revised associations section.
Intro
Recently I decided to make a to-do list application with Nodejs for my portfolio. You can view the semi-finished product on GitHub. I struggled with Sequelize, an object relational manager for JavaScript and SQL database dialects. In this post I’ll give a full practical description of how to set up an environment of Sequelize tables and create a series of migrations so that you can quickly duplicate that environment for testing and production. We’ll use MySQL in this example but Sequelize works with many dialects of SQL.
Index
Theory
- SQL databases
- How does an ORM (object relational manager) work?
- Models and Migrations
- Structuring Data
Practice
- Tools & Set-Up
- Using the Sequelize CLI
- Sequelize CLI Part II: Generating Models
- Editing Models and Migrations (Not Including Associations/Foreign Keys)
- Model Associations (for Foreign Keys): hasMany, hasOne, belongsTo
- Creating Foreign Keys in Migrations
- Guesses at Many-to-Many Associations: belongsToMany
- Pluralization: Weird or Intuitive?
- Telling the migrations where to run (configuring database environments)
- Calls from within your app
- Testing with Mocha: beforeEach Hooks
- Production: A note on environmental variables
- Resources
Theory
SQL Databases
SQL stands for “structured query language”. SQL databases are unified by a common parent language that builds databases that function a lot like Excel spreadsheets. SQL databases are made up of tables, and each table has columns and rows. The shape of the data makes a “grid” of “cells”. SQL DBs are often thought of as “relational” because each table can store references to other tables through numeric coding. Every row of each table has an “id” that can be used as a reference for that specific row in a “cell” of another row, possibly in another table. So SQL DBs are a natural choice for data that has clear relationships and not a lot of “blank cells”, because even if nothing is stored in a “cell”, that space takes up memory in the database. The shape of a SQL DB’s tables determines the possible kinds of data that the DB can store, and that shape must exist before you can store any data. This is what makes migrations so valuable. They can store a set of instructions for determining that shape nearly instantaneously.
How does an ORM (object relational manager) work?
ORMs are code libraries that allow you to query databases without writing any of the database’s native language yourself. So with the Sequelize ORM, which is designed to be used in a JavaScript environment, you write JavaScript to query a SQL database instead of its dialect of structured query language. This helps simplify your code dramatically and makes it easier to keep your head in the main game, which is writing JavaScript, instead of veering off into the world of SQL entirely. It also keeps your code DRYer (DRY stands for Don’t Repeat Yourself) because you don’t have to write a million SQL queries that are all slightly different from each other. ORMs use “models” to determine the rules for storing a “cell” in one of your tables’ rows. In Sequelize, these models translate JavaScript objects into SQL’s rules to determine whether or not an entry “counts” as a valid piece of data for that “cell”. And these models, in turn, can generate the skeletons for your migrations.
Models and Migrations
A model is a set of criteria that determines what counts as a valid database entry. In a SQL object relational manager, each candidate table row flows through the model, which determines whether the row has the required column-cells and whether those cells are well-formed based on the model’s rules. If the row passes all the model’s checks, it is entered into the database.
A migration is a set of database operations that has an “up” function and a “down” function. The “up” function changes the database and the “down” function attempts to restore the database to how it was before the “up” function ran. You can use migrations for structural database operations, like adding tables, columns, and whatnot, but you can also use migrations to add data (rows) to tables. However, what most people mean when they talk about migrations is the former, structural database operations.
Although migrations are an elegant solution to track series of changes to a database, you’ve got to be just as careful with them as you would be with one-off SQL operations. The reason is this: you can write a “up” migration to drop a table, and a “down” migration to add it back, but unless you include every row that was in the table to start with in your “down” migration, you still lose that table’s data even when the table itself is added back to the database. The situation gets even more complicated when you consider dropping and adding parts of tables.
Despite these limitations, which are inherent to all structural database operations, migrations are an awesome tool to quickly configure and replicate a database environment across a project. For most projects, you’d like to have at least three separate databases. One for messing around with in development, one for testing operations, and one for your finished, deployed app. Why use three? It may seem obvious why separating these concerns makes sense for a large app with customer data, but even in a small project with no important production data, it’s a great idea. It makes it easier for you, the developer, to work your magic. The testing environment will be designed to completely scrap your entire database on each operation, and you’ll run 20-50 of these operations per automated test. Testing plays fast and loose with your data, and you won’t want those tests to interfere with the flow you’ve got going on in your development database. As for production, that database will be on a cloud server somewhere far away from your development database. Simply put, database environments are relatively cheap when you consider the benefits of separating development, testing, and production.
Models are used every time you attempt send data (table rows) through your app and into your database tables. Migrations are used to set up those tables’ columns or to bulk add rows. So while a model and a migration for the same database table may seem repetitive, remember that the model controls what data can enter the database, and migrations actually themselves make changes to the database.
Structuring data
Think long and hard before you generate your models. Because SQL tables determine the shape of possibility for your data, and are relatively cumbersome to manipulate once they contain data, you’ll want to have a clear idea of what you need to record and how it relates. We do this by determining which tables’ data belongs to which other tables’ data, and whether the relationship is one-to-many or many-to-many.
In this project, our database has four tables: Users, Contexts, Tasks, and Sessions. For the moment, don’t worry about the Sessions. If you’re ready to take the plunge and configure express sessions, check out my blog post here.
User is the highest level table in our database. Users don’t belong to contexts or tasks. Contexts belong to users. Think about the view inside the application. A User should only see the Contexts that they’ve added (and the default Contexts added for them upon registration). Imagine one User added a Context of “Grandma’s House”. It would be apropos of nothing in another User’s view. One User can have many Contexts. And one Context can have many Tasks. We should be able to change the Context of a Task, but Tasks are organized into Contexts to make them easier to retrieve. Each Context can have many Tasks, but each Task has only one Context.
So we’ve come up with the following data structure: Many Tasks belong to one Context, and many Contexts belong to one User. Another way to say this is that one Context has many Tasks and one User has many Contexts. We’ll nail down exactly which one applies when we look at defining associations for our Sequelize tables.
Practice
Tools and Set-Up
To do this project, you’ll need to be brave, moderately handy with the terminal, and have Git, Node, and a MySQL graphical user interface installed, such as Sequel Pro for Mac or MySQL workbench for Windows. Install Node via your favorite package manager or download it from Nodejs.org. I like to use Node Version Manager, which allows you to switch between versions. Installing Git is outside my scope; get acquainted with Git.
Create a new repository with GitHub or BitBucket and git clone it to your computer. cd into your repo and run npm init to create a new Node project. Answer the questions as best you can while node generates your package.json file, which will keep a record of all your packages and node configuration. Run the following to add packages:
[pastacode lang=”bash” manual=”npm%20i%20-S%20sequelize%20mysql” message=”” highlight=”” provider=”manual”/]
In addition, install the Sequelize CLI (command line interface) globally:
[pastacode lang=”bash” manual=”sudo%20npm%20i%20-g%20sequelize-cli” message=”” highlight=”” provider=”manual”/]
Finally, we want to add a couple files to our .gitignore file to prevent saving them in the repo. Run touch .gitignore and open it in your favorite text editor. Add the following.
[pastacode lang=”bash” manual=”node_modules%0Aconfig” message=”.gitignore” highlight=”” provider=”manual”/]
The node_modules are large and can be generated in deployment from the package.json file. The config files contain sensitive passwords and such which will be replaced by environment variables on deployment, and so SHOULDN’T be part of the repo.
Using the Sequelize CLI
One of the great things about Sequelize is that it comes with a command line interface that generates skeletal models and migrations for us to expand and customize. Sequelize adds some convention to the configuration-heavy Node environment to make our lives much easier.
Start by running sequelize init in your project’s root directory. This will add a bunch of directories and files to your project. For now, we’re interested in the models directory. Open models. You should find an index.js file that looks something like this:
[pastacode lang=”javascript” manual=”‘use%20strict’%3B%0A%0Avar%20fs%20%20%20%20%20%20%20%20%3D%20require(‘fs’)%3B%0Avar%20path%20%20%20%20%20%20%3D%20require(‘path’)%3B%0Avar%20Sequelize%20%3D%20require(‘sequelize’)%3B%0Avar%20basename%20%20%3D%20path.basename(module.filename)%3B%0Avar%20env%20%20%20%20%20%20%20%3D%20process.env.NODE_ENV%20%7C%7C%20’development’%3B%0Avar%20config%20%20%20%20%3D%20require(__dirname%20%2B%20’%2F..%2Fconfig%2Fconfig.json’)%5Benv%5D%3B%0Avar%20db%20%20%20%20%20%20%20%20%3D%20%7B%7D%3B%0A%0Aif%20(config.use_env_variable)%20%7B%0A%20%20var%20sequelize%20%3D%20new%20Sequelize(process.env%5Bconfig.use_env_variable%5D)%3B%0A%7D%20else%20%7B%0A%20%20var%20sequelize%20%3D%20new%20Sequelize(config.database%2C%20config.username%2C%20config.password%2C%20config)%3B%0A%7D%0A%0Afs%0A%20%20.readdirSync(__dirname)%0A%20%20.filter(function(file)%20%7B%0A%20%20%20%20return%20(file.indexOf(‘.’)%20!%3D%3D%200)%20%26%26%20(file%20!%3D%3D%20basename)%20%26%26%20(file.slice(-3)%20%3D%3D%3D%20′.js’)%3B%0A%20%20%7D)%0A%20%20.forEach(function(file)%20%7B%0A%20%20%20%20var%20model%20%3D%20sequelize%5B’import’%5D(path.join(__dirname%2C%20file))%3B%0A%20%20%20%20db%5Bmodel.name%5D%20%3D%20model%3B%0A%20%20%7D)%3B%0A%0AObject.keys(db).forEach(function(modelName)%20%7B%0A%20%20if%20(db%5BmodelName%5D.associate)%20%7B%0A%20%20%20%20db%5BmodelName%5D.associate(db)%3B%0A%20%20%7D%0A%7D)%3B%0A%0Adb.sequelize%20%3D%20sequelize%3B%0Adb.Sequelize%20%3D%20Sequelize%3B%0A%0Amodule.exports%20%3D%20db%3B” message=”models/index.js” highlight=”” provider=”manual”/]
This model is the root model that will allow Sequelize to read all the other models you make. It connects your app to the database by way of the lowercase sequelize instance of the Sequelize constructor, which, for now, reads the connection configuration set in the config file, places it in the db object, and exports that connection along with all of your models to be read by other files in your app (module.exports = db) That db variable also includes the Sequelize constructor itself.
Go ahead and commit to your repo.
Sequelize CLI Part II: Generating Models
We’ve got our index file connecting our connection and our models. Now, to generate models and migrations: on the CLI, type:
[pastacode lang=”bash” manual=”sequelize%20model%3Acreate%20–name%20User%20–attributes%20%22email%3Astring%2C%20password%3Astring%22″ message=”” highlight=”” provider=”manual”/]
This will create an incomplete User model and an incomplete User migration that we will flesh out. Let’s follow suit with the Context and Task models:
[pastacode lang=”bash” manual=”sequelize%20model%3Acreate%20–name%20Context%20–attributes%20%22name%3Astring%22″ message=”” highlight=”” provider=”manual”/]
[pastacode lang=”bash” manual=”sequelize%20model%3Acreate%20–name%20Task%20–attributes%20%22name%3Astring%2C%20done%3Aboolean%2C%20description%3Atext%22″ message=”” highlight=”” provider=”manual”/]
And, like magic, you should have several files that weren’t there before in your models and migrations directories. The default for generated Sequelize files is camelCase. However, you can specify snake_case by adding the --underscored flag, and you can keep Sequelize from automatically pluralizing the table name by adding --freeze-table-names. Read more about auto-pluralization below.
Commit your work. Now we’re going to edit these files so that they fully reflect the relationships between the data that we intend and validate our data as it’s saved (or not saved if invalid).
Editing Models and Migrations (Not Including Associations/Foreign Keys)
Let’s start with the User model file. The generated file reads as follows:
[pastacode lang=”javascript” manual=”‘use%20strict’%3B%0Amodule.exports%20%3D%20function(sequelize%2C%20DataTypes)%20%7B%0A%20%20var%20User%20%3D%20sequelize.define(‘User’%2C%20%7B%0A%20%20%20%20email%3A%20DataTypes.STRING%2C%0A%20%20%20%20password%3A%20DataTypes.STRING%0A%20%20%7D%2C%20%7B%0A%20%20%20%20classMethods%3A%20%7B%0A%20%20%20%20%20%20associate%3A%20function(models)%20%7B%0A%20%20%20%20%20%20%20%20%2F%2F%20associations%20can%20be%20defined%20here%0A%20%20%20%20%20%20%7D%0A%20%20%20%20%7D%0A%20%20%7D)%3B%0A%20%20return%20User%3B%0A%7D%3B” message=”models/user.js” highlight=”” provider=”manual”/]
We want to make a few changes here. What are they? Well, first it’s important to understand that Sequelize automatically adds three columns to each table: a unique id that acts as the primary key for the table, and createdAt and updatedAt columns, which are self-explanatory. By default, the id column will start at 1 and assign numbers in ascending order. This pattern is okay for small projects, but it lacks sophistication. Deleted rows will leave obvious gaps in the numbering, rows in different tables will have the same ids, and the unique ids won’t all have the same number of digits. So we’re going to alter the id column to assign a UUID to each row. Read more about primary keys and UUIDs. Sequelize has a UUID datatype that will make this a snap.
Additionally, we want to specify that each email must be unique to the database and each User must have a password.
So, make the following changes:
[pastacode lang=”javascript” manual=”‘use%20strict’%3B%0Amodule.exports%20%3D%20function(sequelize%2C%20DataTypes)%20%7B%0A%20%20var%20User%20%3D%20sequelize.define(‘User’%2C%20%7B%0A%20%20%20%20id%3A%20%7B%0A%20%20%20%20%20%20allowNull%3A%20false%2C%0A%20%20%20%20%20%20primaryKey%3A%20true%2C%0A%20%20%20%20%20%20type%3A%20DataTypes.UUID%2C%0A%20%20%20%20%20%20defaultValue%3A%20DataTypes.UUIDV4%0A%20%20%20%20%7D%2C%0A%20%20%20%20email%3A%20%7B%0A%20%20%20%20%20%20type%3A%20DataTypes.STRING%2C%0A%20%20%20%20%20%20unique%3A%20true%0A%20%20%20%20%7D%2C%0A%20%20%20%20password%3A%20%7B%0A%20%20%20%20%20%20type%3A%20DataTypes.STRING%2C%0A%20%20%20%20%20%20allowNull%3A%20false%0A%20%20%20%20%7D%2C%0A%20%20%7D%2C%20%7B%0A%20%20%20%20classMethods%3A%20%7B%0A%20%20%20%20%20%20associate%3A%20function(models)%20%7B%0A%20%20%20%20%20%20%20%20%2F%2F%20associations%20can%20be%20defined%20here%0A%20%20%20%20%20%20%7D%0A%20%20%20%20%7D%0A%20%20%7D)%3B%0A%20%20return%20User%3B%0A%7D%3B” message=”models/user.js” highlight=”” provider=”manual”/]
Now we need to edit the boilerplate User migration to reflect the changes we’ve made to the model in the table’s structure. Notice that while the id, createdAt, and updatedAt columns weren’t present in the original boilerplate User model, they are in the boilerplate User migration. They’re not in the model because the Sequelize node package specifies them as a default part of each model, but they have to be in the migration so that the columns are created in the table. Remember, SQL databases can’t save data unless you’ve previously created columns for that data. Here is the generated boilerplate User migration:
[pastacode lang=”javascript” manual=”‘use%20strict’%3B%0Amodule.exports%20%3D%20%7B%0A%20%20up%3A%20function(queryInterface%2C%20Sequelize)%20%7B%0A%20%20%20%20return%20queryInterface.createTable(‘Users’%2C%20%7B%0A%20%20%20%20%20%20id%3A%20%7B%0A%20%20%20%20%20%20%20%20allowNull%3A%20false%2C%0A%20%20%20%20%20%20%20%20autoIncrement%3A%20true%2C%0A%20%20%20%20%20%20%20%20primaryKey%3A%20true%2C%0A%20%20%20%20%20%20%20%20type%3A%20Sequelize.INTEGER%0A%20%20%20%20%20%20%7D%2C%0A%20%20%20%20%20%20email%3A%20%7B%0A%20%20%20%20%20%20%20%20type%3A%20Sequelize.STRING%0A%20%20%20%20%20%20%7D%2C%0A%20%20%20%20%20%20password%3A%20%7B%0A%20%20%20%20%20%20%20%20type%3A%20Sequelize.STRING%0A%20%20%20%20%20%20%7D%2C%0A%20%20%20%20%20%20createdAt%3A%20%7B%0A%20%20%20%20%20%20%20%20allowNull%3A%20false%2C%0A%20%20%20%20%20%20%20%20type%3A%20Sequelize.DATE%0A%20%20%20%20%20%20%7D%2C%0A%20%20%20%20%20%20updatedAt%3A%20%7B%0A%20%20%20%20%20%20%20%20allowNull%3A%20false%2C%0A%20%20%20%20%20%20%20%20type%3A%20Sequelize.DATE%0A%20%20%20%20%20%20%7D%0A%20%20%20%20%7D)%3B%0A%20%20%7D%2C%0A%20%20down%3A%20function(queryInterface%2C%20Sequelize)%20%7B%0A%20%20%20%20return%20queryInterface.dropTable(‘Users’)%3B%0A%20%20%7D%0A%7D%3B” message=”migrations/user.js” highlight=”” provider=”manual”/]
And here is the migration edited to reflect the changes in the User model.
[pastacode lang=”javascript” manual=”‘use%20strict’%3B%0A%0Amodule.exports%20%3D%20%7B%0A%20%20up%3A%20function%20(queryInterface%2C%20Sequelize)%20%7B%0A%20%20%20%20return%20queryInterface.createTable(‘Users’%2C%20%7B%0A%20%20%20%20%20%20id%3A%20%7B%0A%20%20%20%20%20%20%20%20allowNull%3A%20false%2C%0A%20%20%20%20%20%20%20%20primaryKey%3A%20true%2C%0A%20%20%20%20%20%20%20%20type%3A%20Sequelize.UUID%2C%0A%20%20%20%20%20%20%20%20defaultValue%3A%20Sequelize.UUIDV4%0A%20%20%20%20%20%20%7D%2C%0A%20%20%20%20%20%20email%3A%20%7B%0A%20%20%20%20%20%20%20%20type%3A%20Sequelize.STRING%2C%0A%20%20%20%20%20%20%20%20unique%3A%20true%0A%20%20%20%20%20%20%7D%2C%0A%20%20%20%20%20%20password%3A%20%7B%0A%20%20%20%20%20%20%20%20type%3A%20Sequelize.STRING%2C%0A%20%20%20%20%20%20%20%20allowNull%3A%20false%0A%20%20%20%20%20%20%7D%2C%0A%20%20%20%20%20%20createdAt%3A%20%7B%0A%20%20%20%20%20%20%20%20allowNull%3A%20false%2C%0A%20%20%20%20%20%20%20%20type%3A%20Sequelize.DATE%0A%20%20%20%20%20%20%7D%2C%0A%20%20%20%20%20%20updatedAt%3A%20%7B%0A%20%20%20%20%20%20%20%20allowNull%3A%20false%2C%0A%20%20%20%20%20%20%20%20type%3A%20Sequelize.DATE%0A%20%20%20%20%20%20%7D%0A%20%20%20%20%7D)%3B%0A%20%20%20%20%2F*%0A%20%20%20%20%20%20Add%20altering%20commands%20here.%0A%20%20%20%20%20%20Return%20a%20promise%20to%20correctly%20handle%20asynchronicity.%0A%0A%20%20%20%20%20%20Example%3A%0A%20%20%20%20%20%20return%20queryInterface.createTable(‘users’%2C%20%7B%20id%3A%20Sequelize.INTEGER%20%7D)%3B%0A%20%20%20%20*%2F%0A%20%20%7D%2C%0A%0A%20%20down%3A%20function%20(queryInterface%2C%20Sequelize)%20%7B%0A%20%20%20%20return%20queryInterface.dropTable(‘Users’)%3B%0A%0A%20%20%20%20%2F*%0A%20%20%20%20%20%20Add%20reverting%20commands%20here.%0A%20%20%20%20%20%20Return%20a%20promise%20to%20correctly%20handle%20asynchronicity.%0A%0A%20%20%20%20%20%20Example%3A%0A%20%20%20%20%20%20return%20queryInterface.dropTable(‘users’)%3B%0A%20%20%20%20*%2F%0A%20%20%7D%0A%7D%3B” message=”migrations/user.js” highlight=”” provider=”manual”/]
Commit your work. Now we must make a similar set of changes to the Context and Task models and migrations. Here’s our Context model once we’ve expanded the boilerplate.
[pastacode lang=”javascript” manual=”‘use%20strict’%3B%0Amodule.exports%20%3D%20function(sequelize%2C%20DataTypes)%20%7B%0A%20%20var%20Context%20%3D%20sequelize.define(‘Context’%2C%20%7B%0A%20%20%20%20id%3A%20%7B%0A%20%20%20%20%20%20allowNull%3A%20false%2C%0A%20%20%20%20%20%20primaryKey%3A%20true%2C%0A%20%20%20%20%20%20type%3A%20DataTypes.UUID%2C%0A%20%20%20%20%20%20defaultValue%3A%20DataTypes.UUIDV4%0A%20%20%20%20%7D%2C%0A%20%20%20%20name%3A%20DataTypes.STRING%0A%20%20%7D%2C%20%7B%0A%20%20%20%20classMethods%3A%20%7B%0A%20%20%20%20%20%20associate%3A%20function(models)%20%7B%0A%20%20%20%20%20%20%20%20%2F%2F%20associations%20can%20be%20defined%20here%0A%20%20%20%20%20%20%7D%0A%20%20%20%20%7D%0A%20%20%7D)%3B%0A%20%20return%20Context%3B%0A%7D%3B” message=”models/context.js” highlight=”” provider=”manual”/]
And the migration:
[pastacode lang=”javascript” manual=”‘use%20strict’%3B%0A%0Amodule.exports%20%3D%20%7B%0A%20%20up%3A%20function%20(queryInterface%2C%20Sequelize)%20%7B%0A%20%20%20%20return%20queryInterface.createTable(‘Contexts’%2C%20%7B%0A%20%20%20%20%20%20id%3A%20%7B%0A%20%20%20%20%20%20%20%20allowNull%3A%20false%2C%0A%20%20%20%20%20%20%20%20primaryKey%3A%20true%2C%0A%20%20%20%20%20%20%20%20type%3A%20Sequelize.UUID%2C%0A%20%20%20%20%20%20%20%20defaultValue%3A%20Sequelize.UUIDV4%0A%20%20%20%20%20%20%7D%2C%0A%20%20%20%20%20%20name%3A%20%7B%0A%20%20%20%20%20%20%20%20type%3A%20Sequelize.STRING%0A%20%20%20%20%20%20%7D%2C%0A%20%20%20%20%20%20createdAt%3A%20%7B%0A%20%20%20%20%20%20%20%20allowNull%3A%20false%2C%0A%20%20%20%20%20%20%20%20type%3A%20Sequelize.DATE%0A%20%20%20%20%20%20%7D%2C%0A%20%20%20%20%20%20updatedAt%3A%20%7B%0A%20%20%20%20%20%20%20%20allowNull%3A%20false%2C%0A%20%20%20%20%20%20%20%20type%3A%20Sequelize.DATE%0A%20%20%20%20%20%20%7D%0A%20%20%20%20%7D)%3B%0A%20%20%20%20%2F*%0A%20%20%20%20%20%20Add%20altering%20commands%20here.%0A%20%20%20%20%20%20Return%20a%20promise%20to%20correctly%20handle%20asynchronicity.%0A%0A%20%20%20%20%20%20Example%3A%0A%20%20%20%20%20%20return%20queryInterface.createTable(‘users’%2C%20%7B%20id%3A%20Sequelize.INTEGER%20%7D)%3B%0A%20%20%20%20*%2F%0A%20%20%7D%2C%0A%0A%20%20down%3A%20function%20(queryInterface%2C%20Sequelize)%20%7B%0A%20%20%20%20return%20queryInterface.dropTable(‘Contexts’)%3B%0A%20%20%20%20%2F*%0A%20%20%20%20%20%20Add%20reverting%20commands%20here.%0A%20%20%20%20%20%20Return%20a%20promise%20to%20correctly%20handle%20asynchronicity.%0A%0A%20%20%20%20%20%20Example%3A%0A%20%20%20%20%20%20return%20queryInterface.dropTable(‘users’)%3B%0A%20%20%20%20*%2F%0A%20%20%7D%0A%7D%3B” message=”migrations/context.js” highlight=”” provider=”manual”/]
Commit your work. On to Tasks!
In the Task model, note that we’ve added some extra validation for the Task name. There are all kinds of extra validations you can perform with Sequelize models, but keep in mind that if an entry doesn’t meet every criterion in the model, the row will not be saved at all. It’s important to prevent save failure by using front end validation and back end sanitization to ensure that most data passed to your model can be saved. Writing code to deal with failed database updates is a minefield since there are many reasons an update can fail: at least one for every model validation criterion in addition to actual database errors. However, any mature codebase (which this project is not) will handle failed database updates.
[pastacode lang=”javascript” manual=”‘use%20strict’%3B%0Amodule.exports%20%3D%20function(sequelize%2C%20DataTypes)%20%7B%0A%20%20var%20Task%20%3D%20sequelize.define(‘Task’%2C%20%7B%0A%20%20%20%20id%3A%20%7B%0A%20%20%20%20%20%20allowNull%3A%20false%2C%0A%20%20%20%20%20%20primaryKey%3A%20true%2C%0A%20%20%20%20%20%20type%3A%20DataTypes.UUID%2C%0A%20%20%20%20%20%20defaultValue%3A%20DataTypes.UUIDV4%0A%20%20%20%20%7D%2C%0A%20%20%20%20name%3A%20%7B%0A%20%20%20%20%20%20type%3A%20DataTypes.STRING%2C%0A%20%20%20%20%20%20allowNull%3A%20false%2C%0A%20%20%20%20%20%20validate%3A%20%7B%0A%20%20%20%20%20%20%20%20len%3A%20%7B%0A%20%20%20%20%20%20%20%20%20%20args%3A%20%5B3%2C%2050%5D%2C%0A%20%20%20%20%20%20%20%20%20%20msg%3A%20%22Your%20to-do%20item%20name%20must%20be%20between%203%20and%2050%20characters.%20%20Please%20try%20again.%22%0A%20%20%20%20%20%20%20%20%7D%0A%20%20%20%20%20%20%7D%0A%20%20%20%20%7D%2C%0A%20%20%20%20done%3A%20DataTypes.BOOLEAN%2C%0A%20%20%20%20description%3A%20DataTypes.TEXT%0A%20%20%7D%2C%20%7B%0A%20%20%20%20classMethods%3A%20%7B%0A%20%20%20%20%20%20associate%3A%20function(models)%20%7B%0A%20%20%20%20%20%20%20%20%2F%2F%20associations%20can%20be%20defined%20here%0A%20%20%20%20%20%20%7D%0A%20%20%20%20%7D%0A%20%20%7D)%3B%0A%20%20return%20Task%3B%0A%7D%3B” message=”models/task.js” highlight=”” provider=”manual”/]
Now for the Task migration.
[pastacode lang=”javascript” manual=”‘use%20strict’%3B%0A%0Amodule.exports%20%3D%20%7B%0A%20%20up%3A%20function%20(queryInterface%2C%20Sequelize)%20%7B%0A%20%20%20%20return%20queryInterface.createTable(‘Tasks’%2C%20%7B%0A%20%20%20%20%20%20id%3A%20%7B%0A%20%20%20%20%20%20%20%20allowNull%3A%20false%2C%0A%20%20%20%20%20%20%20%20primaryKey%3A%20true%2C%0A%20%20%20%20%20%20%20%20type%3A%20Sequelize.UUID%2C%0A%20%20%20%20%20%20%20%20defaultValue%3A%20Sequelize.UUIDV4%0A%20%20%20%20%20%20%7D%2C%0A%20%20%20%20%20%20name%3A%20%7B%0A%20%20%20%20%20%20%20%20type%3A%20Sequelize.STRING%2C%0A%20%20%20%20%20%20%20%20allowNull%3A%20false%0A%20%20%20%20%20%20%7D%2C%0A%20%20%20%20%20%20description%3A%20%7B%0A%20%20%20%20%20%20%20%20type%3A%20Sequelize.TEXT%0A%20%20%20%20%20%20%7D%2C%0A%20%20%20%20%20%20done%3A%20%7B%0A%20%20%20%20%20%20%20%20type%3A%20Sequelize.BOOLEAN%0A%20%20%20%20%20%20%7D%2C%0A%20%20%20%20%20%20createdAt%3A%20%7B%0A%20%20%20%20%20%20%20%20allowNull%3A%20false%2C%0A%20%20%20%20%20%20%20%20type%3A%20Sequelize.DATE%0A%20%20%20%20%20%20%7D%2C%0A%20%20%20%20%20%20updatedAt%3A%20%7B%0A%20%20%20%20%20%20%20%20allowNull%3A%20false%2C%0A%20%20%20%20%20%20%20%20type%3A%20Sequelize.DATE%0A%20%20%20%20%20%20%7D%0A%20%20%20%20%7D)%3B%0A%20%20%20%20%2F*%0A%20%20%20%20%20%20Add%20altering%20commands%20here.%0A%20%20%20%20%20%20Return%20a%20promise%20to%20correctly%20handle%20asynchronicity.%0A%0A%20%20%20%20%20%20Example%3A%0A%20%20%20%20%20%20return%20queryInterface.createTable(‘users’%2C%20%7B%20id%3A%20Sequelize.INTEGER%20%7D)%3B%0A%20%20%20%20*%2F%0A%20%20%7D%2C%0A%0A%20%20down%3A%20function%20(queryInterface%2C%20Sequelize)%20%7B%0A%20%20%20%20return%20queryInterface.dropTable(‘Tasks’)%3B%0A%20%20%20%20%2F*%0A%20%20%20%20%20%20Add%20reverting%20commands%20here.%0A%20%20%20%20%20%20Return%20a%20promise%20to%20correctly%20handle%20asynchronicity.%0A%0A%20%20%20%20%20%20Example%3A%0A%20%20%20%20%20%20return%20queryInterface.dropTable(‘users’)%3B%0A%20%20%20%20*%2F%0A%20%20%7D%0A%7D%3B” message=”migrations/task.js” highlight=”” provider=”manual”/]
Commit your work.
Model Associations (for Foreign Keys): hasMany, hasOne, belongsTo
The section on associations in the Sequelize docs is confusing. When should you use hasMany, hasOne, belongsTo, and belongsToMany? The Sequelize docs talk about the source and target models and tables, but doesn’t clearly explain which is which. I THINK that the source table is the table whose rows store the foreign keys corresponding to the target rows’ primary keys.
In Sequelize, an association must be defined on both the target and the source models. For clarity, let’s call them the “model containing the primary key” and the “model containing the foreign key”. The model containing the primary key uses hasMany (1:many) and hasOne (1:1) while the model containing the foreign key uses belongsTo (1:1, 1:many). The name of the foreign key column must be specified on both models, in the associations section. Do not put the foreign key column in the list of columns on the model containing the foreign key. You will get the error that the column already exists, because Sequelize will try to create it twice. Instead, only define the foreign key in the associations section. This project only uses one-to-many relationships, so check out the Sequelize docs section on associations for one-to-one and many-to-many associations. As of this writing, the docs text seems to be right, if not clear or laden with examples. I’ve added a short summary on many-to-many associations in models and migrations a few sections down.
Let’s define the model associations for the User. We’ll handle migrations separately in the section below. We want to associate the User model with the Context model by specifying that a User has many Contexts, and pass the name of the foreign key in the Context model (model containing the foreign key) to the User model (model containing the primary key). We’ve also specified onDelete: CASCADE, which tells Sequelize that if we delete a User, it should delete all that User’s Contexts. I’m not sure if this needs to be specified on the model containing the primary key, but I’ve included it to be future-proof. The other option is onDelete: 'SET NULL'.
[pastacode lang=”javascript” manual=”‘use%20strict’%3B%0Amodule.exports%20%3D%20function(sequelize%2C%20DataTypes)%20%7B%0A%20%20var%20User%20%3D%20sequelize.define(‘User’%2C%20%7B%0A%20%20%20%20…%0A%20%20%7D%2C%20%7B%0A%20%20%20%20classMethods%3A%20%7B%0A%20%20%20%20%20%20associate%3A%20function(models)%20%7B%0A%20%20%20%20%20%20%20%20User.hasMany(models.Context%2C%20%7B%0A%20%20%20%20%20%20%20%20%20%20foreignKey%3A%20’UserId’%2C%0A%09%20%20%20%20%20%20onDelete%3A%20’CASCADE’%0A%20%20%20%20%20%20%20%20%7D)%3B%0A%20%20%20%20%20%20%7D%0A%20%20%20%20%7D%0A%20%20%7D)%3B%0A%20%20return%20User%3B%0A%7D%3B%0A” message=”models/user.js” highlight=”8-11″ provider=”manual”/]
In the associations section of the Context model, we’ll specify that each Context belongs to a User and each Task has many Contexts. Wait, didn’t we tell Sequelize that each User has many Contexts? Why do we also need to tell it that each Context belongs to a User? Well, not all database relations are one to many. What if we designed our database so that each User had many Contexts and each Context could have many Users? It would be a logistical mess for this particular database (since Tasks belong to Contexts and not Users), but you can start to see why we need to define the data relationship on both sides of the relation for Sequelize to understand how to store foreign keys. Note that we’ve specified the name of the User-Context foreign key again here on Context, the model containing the foreign key, and the name of the Context-Task foreign key here on Context, the model containing the primary key.
[pastacode lang=”javascript” manual=”‘use%20strict’%3B%0Amodule.exports%20%3D%20function(sequelize%2C%20DataTypes)%20%7B%0A%20%20var%20Context%20%3D%20sequelize.define(‘Context’%2C%20%7B%0A%20%20%20%20…%0A%20%20%7D%2C%20%7B%0A%20%20%20%20classMethods%3A%20%7B%0A%20%20%20%20%20%20associate%3A%20function(models)%20%7B%0A%20%20%20%20%20%20%20%20Context.hasMany(models.Task%2C%20%7B%0A%20%20%20%20%20%20%20%20%20%20foreignKey%3A%20’ContextId’%2C%0A%09%20%20%20%20%20%20onDelete%3A%20’CASCADE’%0A%20%20%20%20%20%20%20%20%7D)%3B%0A%20%20%20%20%20%20%20%20Context.belongsTo(models.User%2C%20%7B%0A%20%20%20%20%20%20%20%20%20%20foreignKey%3A%20’UserId’%2C%0A%20%20%20%20%20%20%20%20%20%20onDelete%3A%20’CASCADE’%0A%20%20%20%20%20%20%20%20%7D)%3B%0A%20%20%20%20%20%20%20%20%2F%2F%20associations%20can%20be%20defined%20here%0A%20%20%20%20%20%20%7D%0A%20%20%20%20%7D%0A%20%20%7D)%3B%0A%20%20return%20Context%3B%0A%7D%3B%0A” message=”models/context.js” highlight=”8-15″ provider=”manual”/]
Finally on the Task model, we’ll specify the name of the Context-Task foreign key on Task, the model containing the foreign key.
[pastacode lang=”javascript” manual=”‘use%20strict’%3B%0Amodule.exports%20%3D%20function(sequelize%2C%20DataTypes)%20%7B%0A%20%20var%20Task%20%3D%20sequelize.define(‘Task’%2C%20%7B%0A%20%20%20%20…%0A%20%20%7D%2C%20%7B%0A%20%20%20%20classMethods%3A%20%7B%0A%20%20%20%20%20%20associate%3A%20function(models)%20%7B%0A%20%20%20%20%20%20%20%20Task.belongsTo(models.Context%2C%20%7B%0A%20%20%20%20%20%20%20%20%20%20foreignKey%3A%20’ContextId’%2C%0A%20%20%20%20%20%20%20%20%20%20onDelete%3A%20’CASCADE’%0A%20%20%20%20%20%20%20%20%7D)%3B%0A%20%20%20%20%20%20%7D%0A%20%20%20%20%7D%0A%20%20%7D)%3B%0A%20%20return%20Task%3B%0A%7D%3B%0A” message=”models/task.js” highlight=”8-11″ provider=”manual”/]
Commit your work. On to migrations!
Creating Foreign Keys in Migrations
Just like you include the id, createdAt, and updatedAt columns in the migration, but not the model, you must explicitly create the foreign key column on the migration containing the foreign key, along with info about which table the foreign key references. Where the association implies the connection on the model, you must tell the SQL DB itself how to constrain the columns you create in the migration. Read more about foreign keys. There are no changes to the User migration because it does not include any foreign keys.
The UserId column on the Context model stores the foreign key, or the id from the row in the Users table that the particular Context row belongs to. We’ve specified a couple of options for our UserId column: it’s a UUID (no surprise there), it references the id in the corresponding row from the Users table, and there’s that onDelete: CASCADE again. Putting this in the model defines the rules of the association between Context and User for Sequelize, and repeating it in the migration tells the SQL table what to do. If we had somehow specified the association in the CLI boilerplate generation (which may be possible, check out the Sequelize docs), I suspect that the UserId column definition would have been added to the migration exactly as we’ve added it here. onDelete: CASCADE tells Sequelize that if we delete a User, it should delete all that User’s Contexts.
[pastacode lang=”javascript” manual=”‘use%20strict’%3B%0A%0Amodule.exports%20%3D%20%7B%0A%20%20%2F%2Ffunction%20to%20run%20when%20(trying)%20to%20create%20the%20table%20(or%20make%20needed%20changes%20to%20it)%0A%20%20up%3A%20function%20(queryInterface%2C%20Sequelize)%20%7B%0A%20%20%20%20%2F%2Fdefine%20all%20columns%20in%20Contexts%2C%20including%20id%2C%20createdAt%2C%20and%20updatedAt%20as%20well%20as%20foreign%20keys%20(see%20UserId)%0A%20%20%20%20return%20queryInterface.createTable(‘Contexts’%2C%20%7B%0A%20%20%20%20%20%20id%3A%20%7B%0A%20%20%20%20%20%20%20%20allowNull%3A%20false%2C%0A%20%20%20%20%20%20%20%20primaryKey%3A%20true%2C%0A%20%20%20%20%20%20%20%20type%3A%20Sequelize.UUID%2C%0A%20%20%20%20%20%20%20%20defaultValue%3A%20Sequelize.UUIDV4%0A%20%20%20%20%20%20%7D%2C%0A%20%20%20%20%20%20name%3A%20%7B%0A%20%20%20%20%20%20%20%20type%3A%20Sequelize.STRING%0A%20%20%20%20%20%20%7D%2C%0A%20%20%20%20%20%20UserId%3A%20%7B%0A%20%20%20%20%20%20%20%20type%3A%20Sequelize.UUID%2C%0A%20%20%20%20%20%20%20%20onDelete%3A%20’CASCADE’%2C%0A%20%20%20%20%20%20%20%20references%3A%20%7B%0A%20%20%20%20%20%20%20%20%20%20model%3A%20’Users’%2C%0A%20%20%20%20%20%20%20%20%20%20key%3A%20’id’%0A%20%20%20%20%20%20%20%20%7D%0A%20%20%20%20%20%20%7D%2C%0A%20%20%20%20%20%20createdAt%3A%20%7B%0A%20%20%20%20%20%20%20%20allowNull%3A%20false%2C%0A%20%20%20%20%20%20%20%20type%3A%20Sequelize.DATE%0A%20%20%20%20%20%20%7D%2C%0A%20%20%20%20%20%20updatedAt%3A%20%7B%0A%20%20%20%20%20%20%20%20allowNull%3A%20false%2C%0A%20%20%20%20%20%20%20%20type%3A%20Sequelize.DATE%0A%20%20%20%20%20%20%7D%0A%20%20%20%20%7D)%3B%0A%20%20%7D%2C%0A%20%20%2F%2Ffunction%20to%20run%20when%20reverting%20the%20changes%20to%20the%20table%0A%20%20down%3A%20function%20(queryInterface%2C%20Sequelize)%20%7B%0A%20%20%20%20return%20queryInterface.dropTable(‘Contexts’)%3B%0A%20%20%7D%0A%7D%3B%0A” message=”migrations/context.js” highlight=”17-24″ provider=”manual”/]
And we’ll do the same on the Task model.
[pastacode lang=”javascript” manual=”‘use%20strict’%3B%0A%0Amodule.exports%20%3D%20%7B%0A%20%20%2F%2Ffunction%20to%20run%20when%20(trying)%20to%20create%20the%20table%20(or%20make%20needed%20changes%20to%20it)%0A%20%20up%3A%20function%20(queryInterface%2C%20Sequelize)%20%7B%0A%20%20%20%20%2F%2Fdefine%20all%20columns%20in%20Tasks%2C%20including%20id%2C%20createdAt%2C%20and%20updatedAt%20as%20well%20as%20foreign%20keys%20(see%20ContextId)%0A%20%20%20%20return%20queryInterface.createTable(‘Tasks’%2C%20%7B%0A%20%20%20%20%20%20id%3A%20%7B%0A%20%20%20%20%20%20%20%20allowNull%3A%20false%2C%0A%20%20%20%20%20%20%20%20primaryKey%3A%20true%2C%0A%20%20%20%20%20%20%20%20type%3A%20Sequelize.UUID%2C%0A%20%20%20%20%20%20%20%20defaultValue%3A%20Sequelize.UUIDV4%0A%20%20%20%20%20%20%7D%2C%0A%20%20%20%20%20%20name%3A%20%7B%0A%20%20%20%20%20%20%20%20type%3A%20Sequelize.STRING%2C%0A%20%20%20%20%20%20%20%20allowNull%3A%20false%0A%20%20%20%20%20%20%7D%2C%0A%20%20%20%20%20%20description%3A%20%7B%0A%20%20%20%20%20%20%20%20type%3A%20Sequelize.TEXT%0A%20%20%20%20%20%20%7D%2C%0A%20%20%20%20%20%20done%3A%20%7B%0A%20%20%20%20%20%20%20%20type%3A%20Sequelize.BOOLEAN%0A%20%20%20%20%20%20%7D%2C%0A%20%20%20%20%20%20ContextId%3A%20%7B%0A%20%20%20%20%20%20%20%20type%3A%20Sequelize.UUID%2C%0A%20%20%20%20%20%20%20%20onDelete%3A%20’CASCADE’%2C%0A%20%20%20%20%20%20%20%20references%3A%20%7B%0A%20%20%20%20%20%20%20%20%20%20model%3A%20’Contexts’%2C%0A%20%20%20%20%20%20%20%20%20%20key%3A%20’id’%0A%20%20%20%20%20%20%20%20%7D%0A%20%20%20%20%20%20%7D%2C%0A%20%20%20%20%20%20createdAt%3A%20%7B%0A%20%20%20%20%20%20%20%20allowNull%3A%20false%2C%0A%20%20%20%20%20%20%20%20type%3A%20Sequelize.DATE%0A%20%20%20%20%20%20%7D%2C%0A%20%20%20%20%20%20updatedAt%3A%20%7B%0A%20%20%20%20%20%20%20%20allowNull%3A%20false%2C%0A%20%20%20%20%20%20%20%20type%3A%20Sequelize.DATE%0A%20%20%20%20%20%20%7D%0A%20%20%20%20%7D)%3B%0A%20%20%7D%2C%0A%20%20%2F%2Ffunction%20to%20run%20when%20reverting%20the%20changes%20to%20the%20table%0A%20%20down%3A%20function%20(queryInterface%2C%20Sequelize)%20%7B%0A%20%20%20%20return%20queryInterface.dropTable(‘Tasks’)%3B%0A%20%20%7D%0A%7D%3B%0A” message=”migrations/task.js” highlight=”24-31″ provider=”manual”/]
Commit your work.
Guesses at Many-to-Many Associations: belongsToMany
Many:many relationships break the mold and belongsToMany is defined on both of the models with no association on the join table. Each association must give the name of the join table in a “through” property, with foreignKey and onDelete, etc. I am not sure whether the join table even needs a model (unless you want to define just its primary key to make it a UUID, since foreign key columns are not in the model), but it seems like you should definitely create a migration for it to create the foreign key columns. I haven’t tried it and I think it makes the nomenclature for associations even more weird and counter-intuitive. Here’s a example of how I think it works unrelated to this project.
[pastacode lang=”javascript” manual=”…%0A%7D%2C%20%7B%0A%09classMethods%3A%20%7B%0A%09%09associate%3A%20function(models)%20%7B%0A%09%09%09TableA.belongsToMany(models.TableB%2C%20%7B%0A%09%09%09%09%20through%3A%20models.JoinTable%2C%0A%09%09%09%09%20foreignKey%3A%20’TableAId’%2C%0A%09%09%09%09%20onDelete%3A%20’CASCADE’%0A%09%09%7D)%3B%0A%09%7D%0A%7D%20…” message=”models/TableA.js” highlight=”” provider=”manual”/]
[pastacode lang=”javascript” manual=”…%0A%7D%2C%20%7B%0A%09classMethods%3A%20%7B%0A%09%09associate%3A%20function(models)%20%7B%0A%09%09%09TableB.belongsToMany(models.TableA%2C%20%7B%0A%09%09%09%09%20through%3A%20models.JoinTable%2C%0A%09%09%09%09%20foreignKey%3A%20’TableBId’%2C%0A%09%09%09%09%20onDelete%3A%20’CASCADE’%0A%09%09%7D)%3B%0A%09%7D%0A%7D%20…” message=”models/TableB.js” highlight=”” provider=”manual”/]
[pastacode lang=”javascript” manual=”…%0A%0A%2F%2Fprimary%20key%20definition%0A%0A%09TableAId%3A%20%7B%0A%20%20%20%20%20%20%20type%3A%20Sequelize.UUID%2C%0A%20%20%20%20%20%20%20onDelete%3A%20’CASCADE’%2C%0A%20%20%20%20%20%20%20references%3A%20%7B%0A%20%20%20%20%20%20%20%20%20%20%20%20model%3A%20’TableA’%2C%0A%20%20%20%20%20%20%20%20%20%20%20%20key%3A%20’id’%0A%20%20%20%20%20%20%20%7D%0A%09%7D%2C%0A%0A%09TableBId%3A%20%7B%0A%20%20%20%20%20%20%20type%3A%20Sequelize.UUID%2C%0A%20%20%20%20%20%20%20onDelete%3A%20’CASCADE’%2C%0A%20%20%20%20%20%20%20references%3A%20%7B%0A%20%20%20%20%20%20%20%20%20%20%20%20model%3A%20’TableB’%2C%0A%20%20%20%20%20%20%20%20%20%20%20%20key%3A%20’id’%0A%20%20%20%20%20%20%20%7D%0A%09%7D%2C%0A%0A…” message=”migrations/JoinTable.js” highlight=”” provider=”manual”/]
Pluralization: Weird or Intuitive?
You might also ask why the model name is given as “Users” but the user model filename is “user.js” and the actual text of the User model says “User”, not “Users” in several places. Take a look at the User migration. The actual table in the database is called “Users”. This convention of pluralizing the table name while the model definition is singular comes from Ruby on Rails and is intended to express that the model applies to individual database entries as they enter the database and the table is a collection of these entries. Some find this confusing and it’s possible to “freeze table names” in Sequelize so that this doesn’t happen (see Generating Models above). Take a look at the docs for more info. However, since this article is about how Sequelize brings a little organization/sanity to the Node environment via the Rails “convention over configuration” ethos, I’ve left the dynamic and pluralized while the models are singular.
Telling migrations where to run (configuring database environments)
Now we have a bunch of lovely models and a great database structure with our migrations, but we don’t have a database yet. Let’s fix that. We’re going to create development and test databases, update our config file to reflect the databases we’ve made so we can connect to them, and migrate the structure we’ve created into both databases.
Install MySQL, PostgreSQL, MariaDB, SQLite or MSSQL on your machine. Sequelize works with all of these. I’m going to give instructions using MySQL and the Mac GUI Sequel Pro to manipulate the DB. Here are instructions to install MySQL on a Mac.
Start the MySQL server by heading to the Terminal and typing mysql.server start. Open up Sequel Pro and enter your connection credentials. Select “Add Database” from the dropdown on the upper left and enter a development database name. Repeat the step and enter a test database name. The production database will be on a server somewhere like Heroku, so don’t worry about it for now.

Now to update our config.json file. Remember, DON’T save this file in your repo or it’s totally your fault if you get hacked. An example can be found in my repo under config-example.json. As you can see, it creates several different environments with different databases that your index.js model can connect to. You can create more with different names and credentials if you have need.
[pastacode lang=”javascript” manual=”%7B%0A%20%20%22development%22%3A%20%7B%0A%20%20%20%20%22username%22%3A%20%22root%22%2C%0A%20%20%20%20%22password%22%3A%20null%2C%0A%20%20%20%20%22database%22%3A%20%22seq-wp-dev%22%2C%0A%20%20%20%20%22host%22%3A%20%22127.0.0.1%22%2C%0A%20%20%20%20%22dialect%22%3A%20%22mysql%22%0A%20%20%7D%2C%0A%20%20%22test%22%3A%20%7B%0A%20%20%20%20%22username%22%3A%20%22root%22%2C%0A%20%20%20%20%22password%22%3A%20null%2C%0A%20%20%20%20%22database%22%3A%20%22seq-wp-test%22%2C%0A%20%20%20%20%22host%22%3A%20%22127.0.0.1%22%2C%0A%20%20%20%20%22dialect%22%3A%20%22mysql%22%0A%20%20%7D%2C%0A%20%20%22production%22%3A%20%7B%0A%20%20%20%20%22username%22%3A%20%22%3F%22%2C%0A%20%20%20%20%22password%22%3A%20%22%3F%22%2C%0A%20%20%20%20%22database%22%3A%20%22%3F%22%2C%0A%20%20%20%20%22host%22%3A%20%22%3F%22%2C%0A%20%20%20%20%22dialect%22%3A%20%22%3F%22%0A%20%20%7D%0A%7D” message=”config/config.json” highlight=”” provider=”manual”/]
Let’s run our migrations to configure our database in both the development and test environments. Go to the Terminal, cd into your project repo, and type:
[pastacode lang=”bash” manual=”sequelize%20db%3Amigrate” message=”” highlight=”” provider=”manual”/]
This will run your migrations in the development environment. Again for the test environment:
[pastacode lang=”bash” manual=”sequelize%20db%3Amigrate%20–env%20test” message=”” highlight=”” provider=”manual”/]
Undo a migration with sequelize db:migrate:undo. If you need to change a model or add/subtract something to/from a whose migration you’ve already run, use sequelize migration:create to generate a fresh migration skeleton. They’re prefixed with the date so they’ll stack up in the order you create them, and they’ll run alpha filename order. Beware that if you have multiple migrations in the directory when you hit db:migrate, they’ll all run immediately. For more fine-grained control, move the later migrations out of the directory and run them one at a time by dropping each one back in the directory when the previous one is complete. See a fuller list of commands over at the docs’ bit on migrations.
In development, don’t be afraid to run and revert migrations over and over and over until you get them right. You’ll sweat and swear, but you won’t break anything. The screenshot below looks super neat and great but in practice you’ll be doing and undoing them over and over until you get the syntax and the desired DB changes exactly right, especially on the development database.
When successful, your terminal should look something like this:
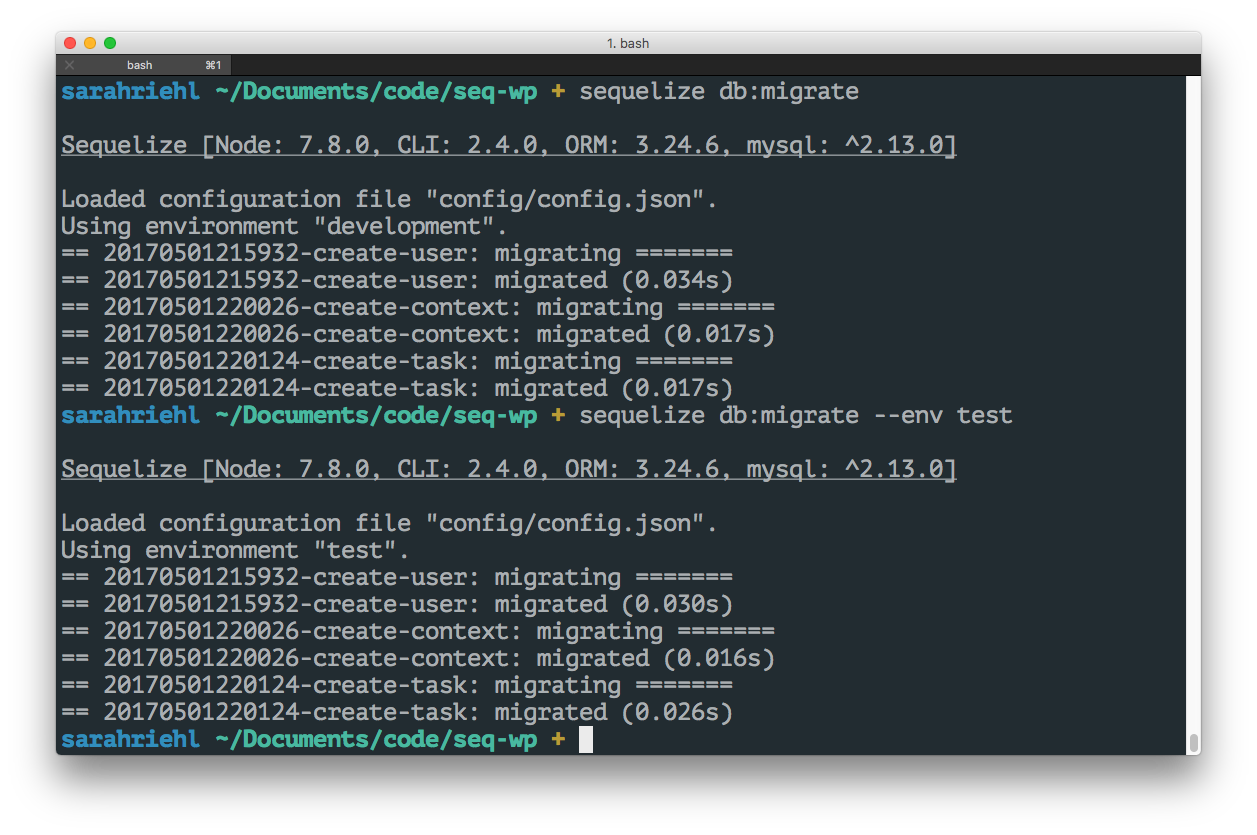
We don’t have to specify the development environment when we run the development migration because development is configured as the default environment in the index.js model.
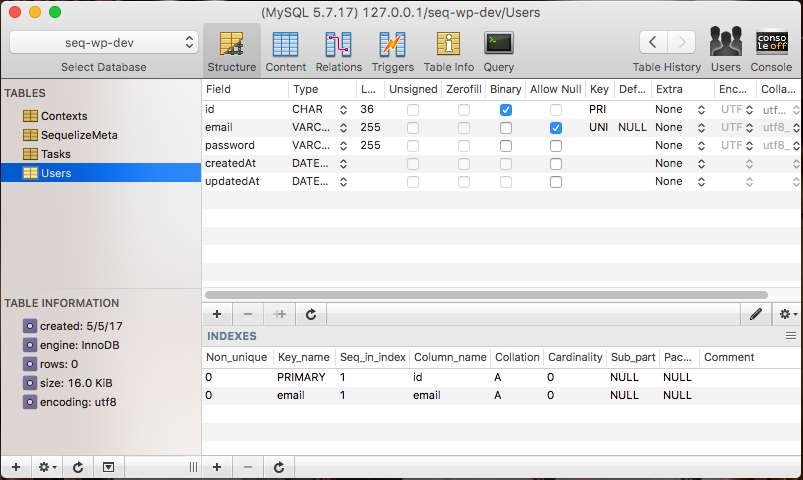
Now when you view your databases in Sequel Pro, you should see all the new columns when you select a table.
Calls from within your app
Check out the Sequelize docs and Codementor’s tutorial to learn how to query your data with Sequelize’s promise-based syntax. Learn more about promises, especially then and catch. I wrote also an article about Javascript promises.
Testing with Mocha: beforeEach hooks
Mocha is a great test suite for Node, which in combination with other utilities like Chai and Nightmare can help you write great automated unit tests for your code. Once you’ve got tests, you can run them every time you change the app to see if you’ve broken anything. I can hardly convey how awesome this is for you as a developer.
One important part of writing automated tests is configuring a perfectly controlled vanilla test environment that is exactly the same for each test. Since each test changes the database, you need to reset it before you run each test. Mocha has a great tool for doing this called a beforeEach hook. Here’s what a good sequelize database reset in a Mocha beforeEach hook should look like for this Sequelize app.
[pastacode lang=”javascript” manual=”beforeEach(‘clear%20and%20add’%2C%20function(done)%20%7B%0A%0A%20%20models.sequelize.query(‘SET%20FOREIGN_KEY_CHECKS%20%3D%200’)%0A%20%20%20%20.then(function()%7B%0A%20%20%20%20%20%20models.sequelize.options.maxConcurrentQueries%20%3D%201%3B%0A%20%20%20%20%20%20return%20models.sequelize.sync(%7B%20force%3A%20true%20%7D)%3B%0A%20%20%20%20%7D)%0A%20%20%20%20.then(function()%7B%0A%20%20%20%20%20%20return%20models.sequelize.query(‘SET%20FOREIGN_KEY_CHECKS%20%3D%201’)%3B%0A%20%20%20%20%7D)%0A%20%20%20%20.then(function()%20%7B%0A%09%20%20let%20user%20%3D%20%7B%0A%20%20%20%20%09email%3A%20’susan%40example.com’%2C%0A%20%20%20%20%09password%3A%20bcrypt.hashSync(%22fakepassword123%22%2C%20bcrypt.genSaltSync(10))%0A%20%20%09%20%20%20%7D%0A%20%20%20%20%20%20return%20models.User%0A%20%20%20%20%20%20%20%20.create(user)%3B%0A%20%20%20%20%7D)%0A%20%20%20%20.then(function(data)%20%7B%0A%20%20%20%20%20%20return%20data.dataValues.id%3B%0A%20%20%20%20%7D)%0A%20%20%20%20.then(function(UserId)%20%7B%0A%20%20%20%20%20%20return%20models.Context%0A%20%20%20%20%20%20%20%20.bulkCreate(%5B%7B%0A%20%20%20%20%20%20%20%20%20%20name%3A%20’Home’%2C%0A%20%20%20%20%20%20%20%20%20%20UserId%0A%20%20%20%20%20%20%20%20%7D%2C%20%7B%0A%20%20%20%20%20%20%20%20%20%20name%3A%20’Work’%2C%0A%20%20%20%20%20%20%20%20%20%20UserId%0A%20%20%20%20%20%20%20%20%7D%2C%20%7B%0A%20%20%20%20%20%20%20%20%20%20name%3A%20’Phone’%2C%0A%20%20%20%20%20%20%20%20%20%20UserId%0A%20%20%20%20%20%20%20%20%7D%2C%20%7B%0A%20%20%20%20%20%20%20%20%20%20name%3A%20’Computer’%2C%0A%20%20%20%20%20%20%20%20%20%20UserId%0A%20%20%20%20%20%20%20%20%7D%5D)%0A%20%20%20%20%7D)%0A%20%20%20%20.then(function(data)%20%7B%0A%20%20%20%20%20%20return%20Promise.resolve(done())%3B%0A%20%20%20%20%7D)%0A%20%20%20%20.catch(function(error)%20%7B%0A%20%20%20%20%20%20console.log(error)%3B%0A%20%20%20%20%20%20return%20Promise.reject(done())%3B%0A%20%20%20%20%7D)%3B%0A%7D)%3B” message=”excerpt from test/test-skeleton.js” highlight=”” provider=”manual”/]
Production: A note on environmental variables
Even though your config.json file has an entry for a production database, in practice, you’ll never use it. This is because in production you want to configure your database connection through an environment variable, rather than in plain text. Some people prefer to upload and unzip tarballs of json configuration files and reference them instead of using env vars. I prefer env vars. I think it’s more secure and the only way to go in production. This will ultimately require some changes to your index.js model. Here’s a snippet from the index.js model configured to deploy to Heroku using a JawsDB MySQL database:
[pastacode lang=”javascript” manual=”‘use%20strict’%3B%0A%0A…%0A%0Avar%20env%20%3D%20process.env.NODE_ENV%20%7C%7C%20’development’%3B%0A%0A…%0A%0Aif(process.env.JAWSDB_URL)%20%7B%0A%20%20var%20sequelize%20%3D%20new%20Sequelize(process.env.JAWSDB_URL)%3B%0A%7D%20else%20%7B%0A%20%20var%20config%20%3D%20require(__dirname%20%2B%20’%2F..%2Fconfig%2Fconfig.json’)%5Benv%5D%3B%0A%20%20if(config.use_env_variable)%20%7B%0A%20%20%20%20var%20sequelize%20%3D%20new%20Sequelize(process.env%5Bconfig.use_env_variable%5D)%3B%0A%20%20%7D%20else%20%7B%0A%20%20%20%20var%20sequelize%20%3D%20new%20Sequelize(config.database%2C%20config.username%2C%20config.password%2C%20config)%3B%0A%20%20%7D%0A%7D%0A%0A…” message=”excerpt from future models/index.js” highlight=”” provider=”manual”/]
Resources
And that’s pretty much it. Check out the repo at https://github.com/slsriehl/seq-wp. Here are some articles I used to learn this stuff.
- The Sequelize docs
- Alex Booker’s general videos (Code Cast)
- Greg Trowbridge on migrations
- Chloe Echikson’s talk on migrations
- Michael Herman’s ‘Node, Postgres, and Sequelize’
- J. Muturi on Node, Express and Postgres Using Sequelize (scotch.io)
- Loren Stewart on associations
- Hari Das for Codementor
- Bulkan Evcimen on using Sequelize with an existing database
 Sarah is a freelance JavaScript developer in Austin, TX USA.
Sarah is a freelance JavaScript developer in Austin, TX USA.
This is beautiful! Thank you very much, this is helping me fine-tune my Sequelize db.
Thanks Michael! Anything you have more questions about?
What even need of sequileze query if we are going to write migration by hand, unlike django which makemigration for us.
can’t we write direct sql
I’m trying to query the db using Postman, and I can create & list out my users just fine, but I’m not able to retrieve a specific user with their UUID. Not quite sure why because I previously had an auto-incrementing id and was able to pull user data that way easily. This is my controller:
retrieve(req, res) {
return User
.findById(req.params.userId, {
include: [
{
model: Job,
as: ‘jobs’,
},
{
model: JobApp,
as: ‘jobApps’,
},
],
})
.then(user => {
if (!user) {
return res.status(404).send({
message: ‘User not found’,
});
}
return res.status(200).send(user);
})
.catch(error => res.status(400).send(error));
},
I plug in the id for the user, but it just gives me the 404 user not found message. My routes are here:
// Creating users
app.post(‘/api/user’, userController.create);
app.get(‘/api/user’, userController.list);
app.get(‘/api/user/:id’, userController.retrieve);
Any ideas?
In the query you’re calling the param userId, but in the route it’s called :id. Try querying req.params.id. Also, pass req and res to the retrieve function when you call it in the route.
Should be
app.get(‘/api/user/:id’, (req, res) => {
userController.retrieve(req, res);
});
Haha in addition to that (thank you for pointing it out), I realized in some cases I was ‘eagerly’ loading data in Sequelize that wasn’t there. Apparently, Sequelize will just throw a fatal error if there is even one little thing wrong – as it should!
On a side note, I really like the articles on your site in general. Using Promises (async), ORM’s for a SQL database and Serverless are REALLY great topics, especially for self-taught folks like me that want to have production ready tools, considering our limited experience.
Anything else you’d like to see? Right now I’m thinking about a post on express sessions and cookies vs. JSON web tokens. And plans for some serverless stuff the road once I do more with it.
Thanks! One of the not so many good ones. I thought I’d spend the night ‘googling’.
Thanks Oke! Anything else you’d like to see an article on?
I’d love to see an article on setting up React-express-webpack for development (maybe for a non trivial project) . That would make it a great christmas 🙂 I’ve had this issue with webpack for days.
Cool, I’ll try to put up my learnings before Christmas.
That would be very nice. Thank you!
I got an error when i do a migration
sequelize db:migrate
crypto.js:70
this._handle.update(data, encoding);
^
TypeError: Not a string or buffer
at TypeError (native)
at Hash.update (crypto.js:70:16)
at sha1 (/home/dontito/NodeORMs/node_modules/mysql2/lib/auth_41.js:30:8)
at Object.token [as calculateToken] (/home/dontito/NodeORMs/node_modules/mysql2/lib/auth_41.js:64:16)
at new HandshakeResponse (/home/dontito/NodeORMs/node_modules/mysql2/lib/packets/handshake_response.js:28:24)
at ClientHandshake.sendCredentials (/home/dontito/NodeORMs/node_modules/mysql2/lib/commands/client_handshake.js:51:27)
at ClientHandshake.handshakeInit (/home/dontito/NodeORMs/node_modules/mysql2/lib/commands/client_handshake.js:142:10)
at ClientHandshake.Command.execute (/home/dontito/NodeORMs/node_modules/mysql2/lib/commands/command.js:40:20)
at Connection.handlePacket (/home/dontito/NodeORMs/node_modules/mysql2/lib/connection.js:502:28)
at PacketParser.onPacket (/home/dontito/NodeORMs/node_modules/mysql2/lib/connection.js:81:16)
at PacketParser.executeStart (/home/dontito/NodeORMs/node_modules/mysql2/lib/packet_parser.js:77:14)
at Socket. (/home/dontito/NodeORMs/node_modules/mysql2/lib/connection.js:89:29)
at emitOne (events.js:77:13)
at Socket.emit (events.js:169:7)
at readableAddChunk (_stream_readable.js:146:16)
at Socket.Readable.push (_stream_readable.js:110:10)
at TCP.onread (net.js:523:20)
Hey Francis,
Migrations are very finicky. Seems like maybe the “up” method of your migration at line 70 isn’t the right datatype? Check the migration code for syntax errors and datatype conformity to any already-existing tables’ models that are involved, especially if you are migrating data and not table structure (seems like you are trying to update the Hash table?). Also, check the default encoding settings in your database engine installation. If that doesn’t work, send me your repo and the name of your migration.
Awesome !!! Great tutorial
Thanks! I hope it helped you.
Hi how can i seed data into my database using the seeders
Hey Daramola,
I haven’t used seeders, so what I know is from the docs. To generate a file from the command line, run
sequelize seed:generate --name some-name. The resulting file looks like a migration file and appears in the seeders directory. Once you’ve got it like you want it, runsequelize db:seedto run a single file (will run the “up” method from the file) andsequelize db:seed:undoto roll it back (will run the “down” method from the file). Based on my experience with migrations, you’ll have to run up and down a couple times until you tweak your code to sequelize’s liking. The main seeders info is from <a href=”http://docs.sequelizejs.com/manual/tutorial/migrations.html#bootstrapping” rel=”nofollow”>http://docs.sequelizejs.com/manual/tutorial/migrations.html#bootstrapping</a>. For a list of commands, runsequelize --help. Good luck!Thank you so much! It ‘s very helpful
Can you elaborate on the as key for foreign keys
Hey Daramola,
In my understanding, the “as” argument will change the JSON key that the reply from the database gives. Let’s say you’re doing an include (join) on User (primary key id, key name) and Context (primary key id, key designation, foreign key for user is set as UserId in the Context model association). Passing as: ‘foo’ in your include object will give you something like this:
...
data: {
id: 1,
designation: 'kitchen',
foo: {
id: 2,
name: 'Daramola'
}
}
instead of this:
...
data: {
id: 1,
designation: 'kitchen',
UserId: { //or is it User?
id: 2,
name: 'Daramola'
}
}
Hope this helps!
Fantastic! Thanks so much. It clarified so much for me.
This is a really great tutorial, I came here looking for how I can break my models and db connection/config into separate files (where as Alex Booker’s YT tutorials do it all in one file). It helped me accomplish that goal as well as helping me understand many other things things that I haven’t even known about yet (read: sequelize-cli and associations xD), so I sincerely thank you for that.
What I think is silly (maybe I just don’t know enough yet, and that’s why I think it’s silly), is that one has to redo everything in the migration that one has already done in the model. For example, in my User model’s options, I set “freezeTableName” to true. But because in my migration the table’s name was set to “Users” (when I generated the model & migration), I had to change the the table name in the migration to “user” to get the desired effect, making the “freezeTableName” flag completely useless (same goes for my User model’s timestamps – only once I updated the migration to use underscore_case, did it correctly propagate in the db). See what I mean? Similarly, I added the “paranoid” flag to my User model’s options (http://docs.sequelizejs.com/manual/tutorial/models-definition.html#configuration) but found that the column that this flag will generate, as claimed by the docs, was in fact not generated, and I suspect the same sorcery that causes the “freezeTableNames” flag to be ignored is at work here.
Therefore, I suspect that if I could somehow work around the migrations (i.e. delete them completely, and have my models generate the database entities some other way) those flags would not be ignored and the database entities would be properly generated. In Alex Booker’s Youtube videos, he used the “connection.sync()” command to generate his db entities, so I’m wondering if you perhaps know of a way that we can be rid of migrations all together and instead generate the db entities directly from the models?
(That’s assuming that you agree with my underlying assumption that the migrations is what’s causing the models’ options to be ignored. If you disagree with that assumption, please let me know why, and how I can go about getting my models’ options not be ignored).
Hi Lee. I do agree that the migrations’ not having these options set is messing things up in the DB. No need to scrap the migrations, however! They can be a pain in the ass, but they can also guarantee consistent sets of changes across environments. I apologize that this response is several months later, but here’s my fix attempt below.
Scouring the docs for my latest project, I discovered that table migrations take an options object in which you can set these flags, as well as an explicit name for the table. The constraints then transfer to the actual DB instead of making me sad. I am 95% sure this will work for freezeTableNames & paranoid. Please let me know if you find otherwise. When I have time to dig through the source code & link to a list of possible options, I’ll update the article.
Note that for “paranoid”, you do still need to add “deleted_at”/”deletedAt” in the migration, just as you do “created_at”, “updated_at”, etc.
...
return queryInterface.createTable("Attendee", {
...attendeeAttributes,
created_at: {
allowNull: false,
type: Sequelize.DATE
},
updated_at: {
allowNull: false,
type: Sequelize.DATE
},
deleted_at: {
allowNull: true,
type: Sequelize.DATE
},
}, {
freezeTableNames: true,
underscored: true,
paranoid: true,
engine: "InnoDB",
charset: "utf8"
},
"Attendee"
)
.then(
...
connection.sync()does work to sync the models to the DB in a pinch, but it’s unpredictable. Perhaps you removed a column in the model… will.sync()also drop it irrevocably from the table? I don’t know. Once you’re working in a production app, it’s a dangerous proposition. IMO, too many unknown unknowns.However, to use
.sync()with the pre-createdindex.jsmodels/connection/constructor access file generated with the CLI, it’smodels.sequelize.sync(). It does return a promise.Thanks so much for this! It was the only resource I could find to help me fix my SequelizeForeignKeyConstraintError!
Best of Best !!! Thanks so very much.
Thank you, Nice Blog
Hey Sarah. Great post!
Do you know of a better way to automatically generate the Sequelize migration files from an existing model definition instead of having to manually type migration files for each entity?
Thank you!
Hi Jonathas. Short answer: no. Shortcut: get the model all tricked out, then cut & paste, and make sure you change DataTypes. to Sequelize. in the “type” attribute. It’s not fancy, but it does give something to work with.
Thank you so much. I had searched a lot of web guides and official documentation to understand this association and migrations.
You saved me ! 🙂
Wondeful post just wanted to add that if you start with a .sequelizerc file that defines config to be a JS file, the sequelize cli will generate a config.js file which can directly include dotenv library to support process.env.DATABASE_NAME etc variables
Hey, Sarah, please tell me, can i ask u a little question about sequelize by email or other way?
Hi Andrew. Sure. Go ahead & submit an email through the site at https://www.duringthedrive.com/contact/. I do recommend composing in your own window & then pasting to submit. Also, no promises on turnaround time right now. 🙂